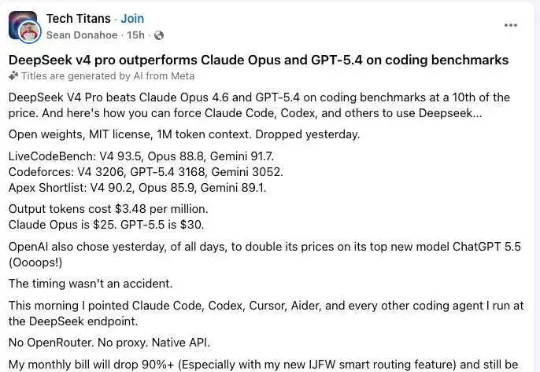
“我把所有模型都换成了DeepSeek V4”:月账单降 90%,效果还更好
“我把所有模型都换成了DeepSeek V4”:月账单降 90%,效果还更好科技博主兼 AI 系统架构师 Sean Donahoe 在今天凌晨发了一条帖子。他写道:这条帖子实际上有两个看点。第一,发帖人是重度 AI 编程用户,却几乎一夜之间完成迁移,月账单会从几千美元降到几百美元。第二,他不只是说便宜,还强调效果没有变差,反而更好:“输出质量提高了,而不是下降,这一点已经通过内部测试以及多个公开基准验证”。
来自主题: AI资讯
8420 点击 2026-04-29 09:42